|
I am currently a Senior Researcher at Kling Team(可灵), Kuaishou Technology, working on Multimodal Generative Foundation Models and World Models. Previously, I was a visiting researcher at ETH Zurich, advised by Prof. Marc Pollefeys. I received my Ph.D. in 2024 from ZJU3DV, State Key Lab of CAD&CG, Zhejiang University, advised by Prof. Hujun Bao and Prof. Guofeng Zhang. I obtained my bachelor's degree from UESTC in 2018. My research goal is to make computers (robotics) learn to perceive, localize, reconstruct, reason, and interact with the real world like humans, that is AGI. I'm interested in Multimodal Video Generation, World Models, 3D Vision Foundation Models, and Embodied AI. We are actively looking for research interns who have strong backgrounds in MLLM, Audio, Video Generation, 3D Vision, etc., to work on cutting-edge research topics. Feel free to email me if you are interested. Email / Google Scholar / Twitter / Github |

|
|
|
* denotes equal contribution, † denotes corresponding author, ‡ denotes project lead. Representative works are highlighted. |
|
Xuanhua He, Quande Liu, Zixuan Ye, Weicai Ye, Qiulin Wang, Xintao Wang, Qifeng Chen Pengfei Wan, Di Zhang, Kun Gai Arxiv 2025 project page / arXiv / code Efficient in-context conditioning framework with dynamical token selection and selective context caching mechanism to address the token redundancy and redundant interactions. Significant Speedup, Reduced Computational Cost, Preserved/Improved Quality. |
|
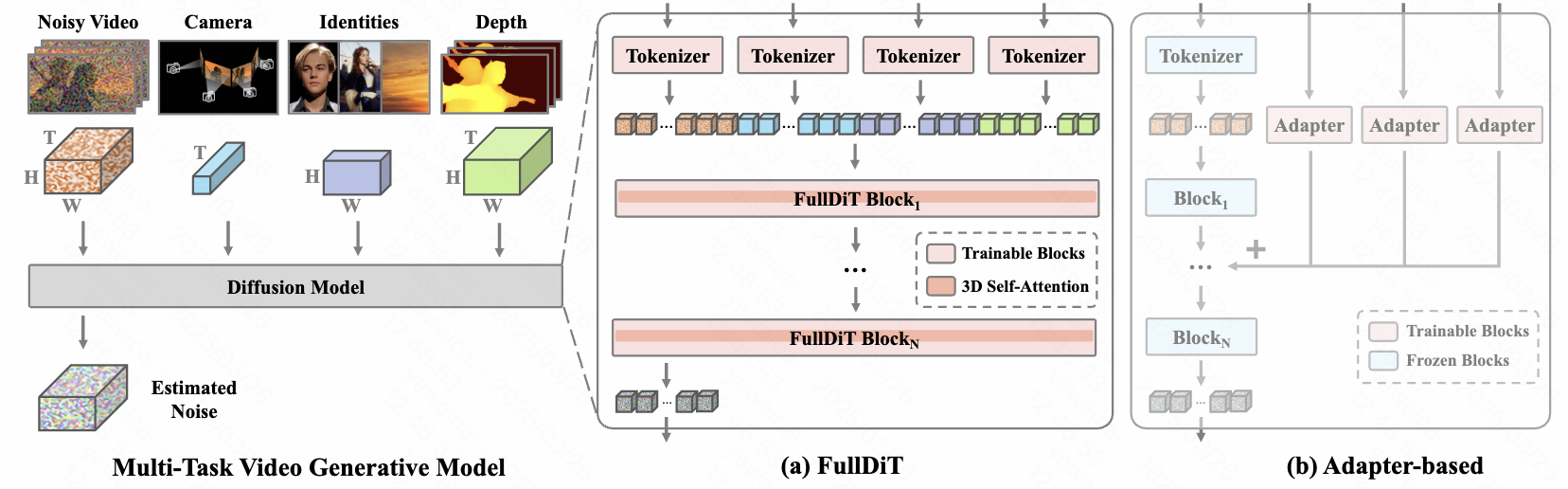
Xuan Ju, Weicai Ye†, Quande Liu, Qiulin Wang, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Qiang Xu ICCV 2025 project page / arXiv / code A unified video generative foundation model that seamlessly integrates multiple conditions, significantly reduces parameter overhead, avoids conflicts common in adapter-based methods, and shows scalability and emergent ability in combining diverse, previously unseen modalities. |
|
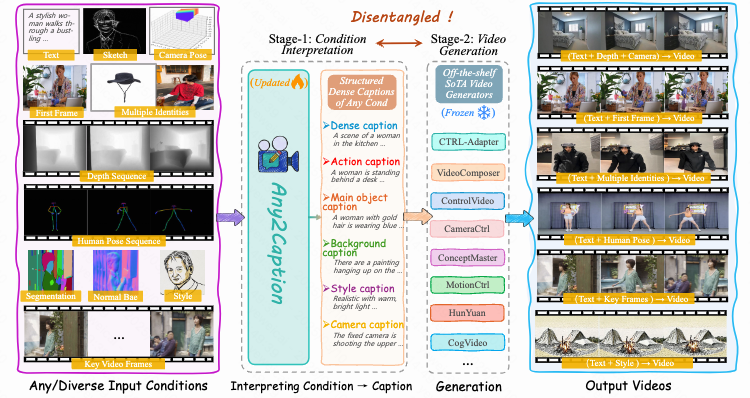
Shengqiong Wu, Weicai Ye†, Jiahao Wang, Quande Liu, Xintao Wang, Pengfei Wan, Di Zhang, Kun Gai, Shuicheng Yan, Hao Fei, Tat-Seng Chua Arxiv 2025 project page / arXiv / code / Top Upvoted of HuggingFace Daily Papers To address the bottleneck of accurate user intent interpretation within current video generation community, present a novel framework that interprets diverse condition into dense, structured captions for controllable video generation from any condition. Significantly improve video quality across various sota video generation models. Propose large-scale high- quality benchmark dataset for any-condition-to-caption task. |
|
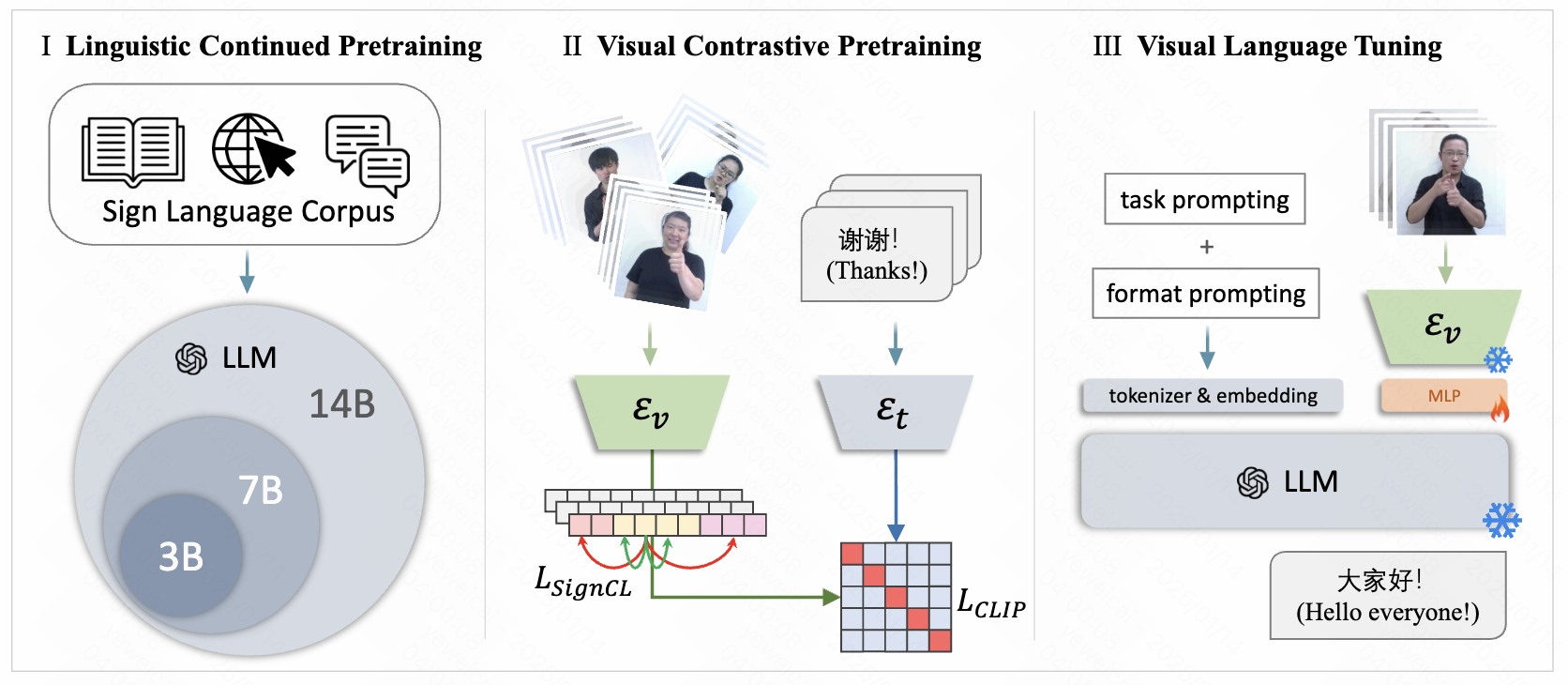
Han Liang, Chengyu Huang, Yuecheng Xu, Cheng Tang, Weicai Ye, Juze Zhang, Xin Chen, Jingyi Yu, Lan Xu Arxiv 2024, Under Review project page / arXiv / code Propose scalable MLMM framework tamed for sign language translation. |

|
Feng-Lin Liu, Hongbo Fu, Xintao Wang, Weicai Ye, Pengfei Wan, Di Zhang, Lin Gao CVPR 2025 project page / arXiv / code Achieved sketch-based spatial and motion control for video generation and support fine-grained editing of real or synthetic videos. |

|
Zhuoman Liu, Weicai Ye†‡, Yan Luximon, Pengfei Wan, Di Zhang CVPR 2025 project page / arXiv / code Unleashing the Potential of Multi-modal Foundation Models and Video Diffusion for 4D Dynamic Physical Scene Simulation with a differentiable Material Point Method (MPM) and optical flow guidance. |
|
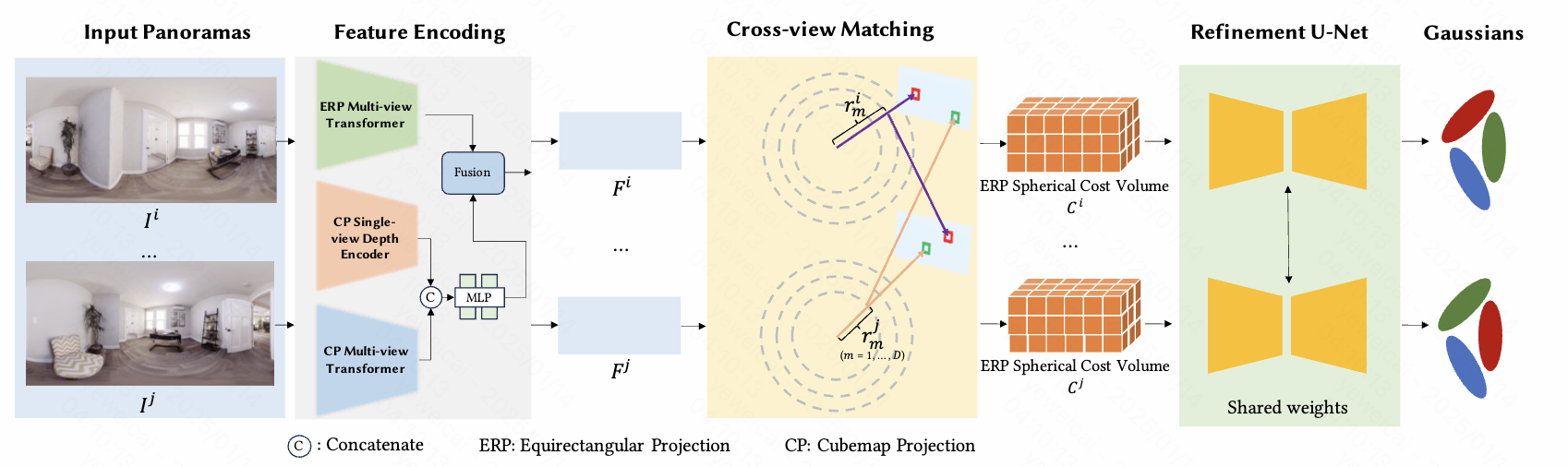
Zheng Chen, Chenming Wu, Zhelun Shen, Chen Zhao, Weicai Ye, Haocheng Feng, Errui Ding, Song-Hai Zhang CVPR 2025 project page / arXiv / code Proposed Generalizable 360∘ Gaussian Splatting for Wide-baseline Panoramic Images |
|
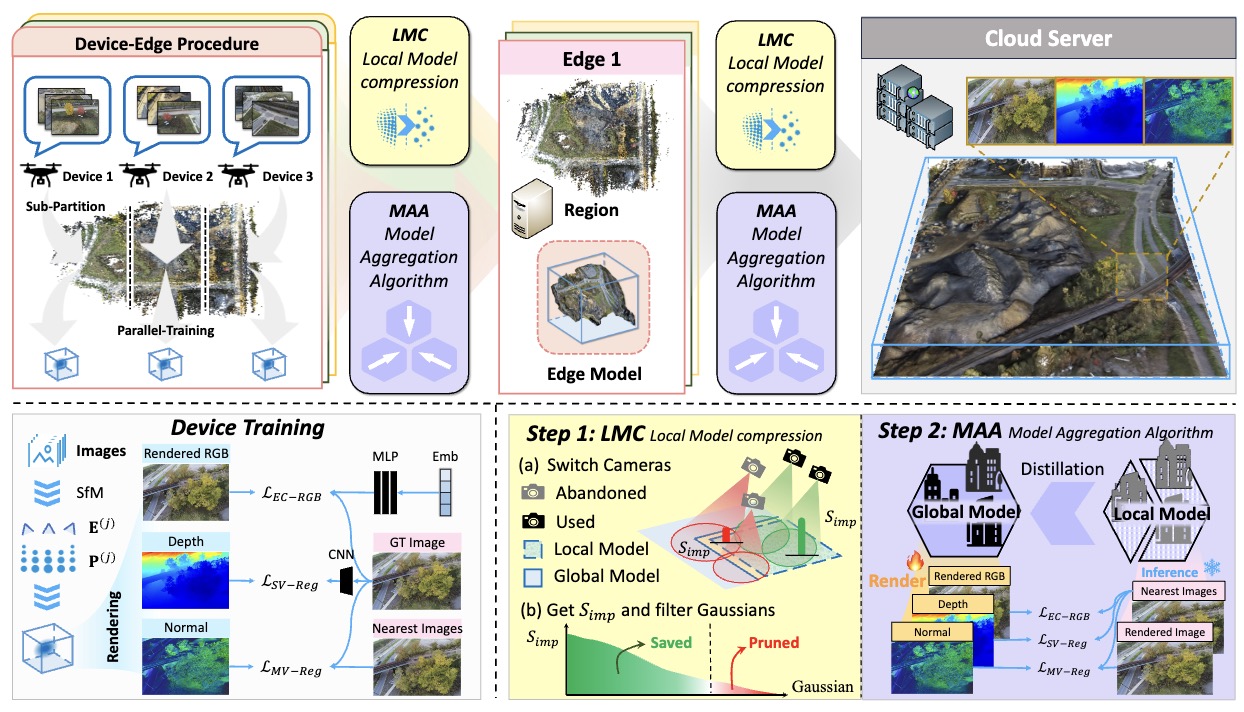
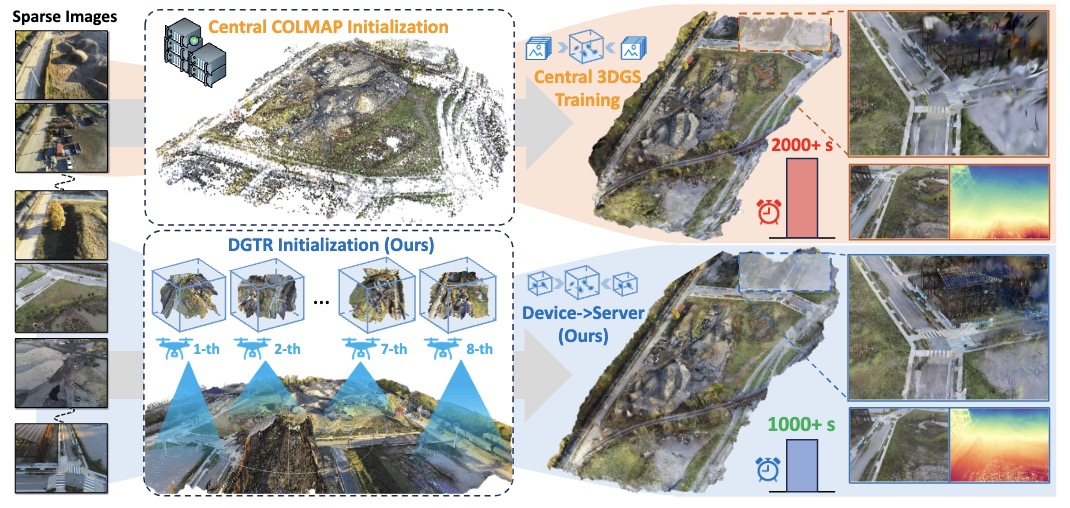
Yuanyuan Gao, Yalun Dai, Hao Li, Weicai Ye†, Junyi Chen, Danpeng Chen, Dingwen Zhang, Tong He, Guofeng Zhang Junwei Han Arxiv 2024 project page / arXiv / code First cloud-edge-device hierarchical framework with Distributed Learning for large-scale high-fidelity surface reconstruction, achieving balance between high-precision reconstruction and low-cost memory. |

|
Junyi Chen, Di Huang, Weicai Ye, Wanli Ouyang, Tong He ICLR 2025 project page / arXiv / code Proposed a novel auto-regressive framework that jointly addresses spatial localization and view prediction. |
|
Yiwen Chen, Tong He, Di Huang, Weicai Ye, Sijin Chen, Jiaxiang Tang, Xin Chen, Zhongang Cai, Lei Yang, Gang Yu, Guosheng Lin, Chi Zhang ICLR 2025 project page / arXiv / code / huggingface MeshAnything mimics human artist in extracting meshes from any 3D representations. It can be combined with various 3D asset production pipelines, such as 3D reconstruction and generation, to convert their results into Artist-Created Meshes that can be seamlessly applied in 3D industry. |

|
Peng Gao, Le Zhuo, Dongyang Liu, Ruoyi Du, Xu Luo, Longtian Qiu, Yuhang Zhang, Rongjie Huang, Shijie Geng, Renrui Zhang, unlin Xie, Wenqi Shao, Zhengkai Jiang, Tianshuo Yang, Weicai Ye, Tong He, Jingwen He, Yu Qiao, Hongsheng Li ICLR 2025, Spotlight, Score: 88866 project page / arXiv / code / demo / huggingface Proposed flow-based large diffusion transformers foundation model for transforming text into any modality (image, video, 3D, Audio, music, etc.), resolution, and duration. |
|
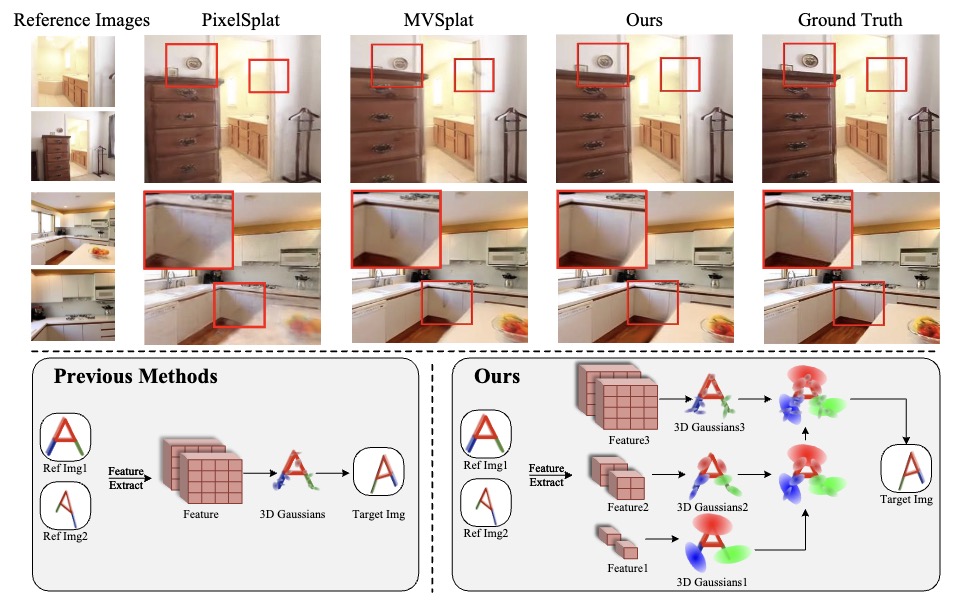
Shengji Tang, Weicai Ye†, Peng Ye, Weihao Lin, Yang Zhou, Tao Chen, Wanli Ouyang ICLR 2025 project page / arXiv / code Proposed a hierarchical manner in generalizable 3D Gaussian Splatting to construct hierarchical 3D Gaussians via a coarse-to-fine strategy, which significantly enhances reconstruction quality and cross-dataset generalization. |
|
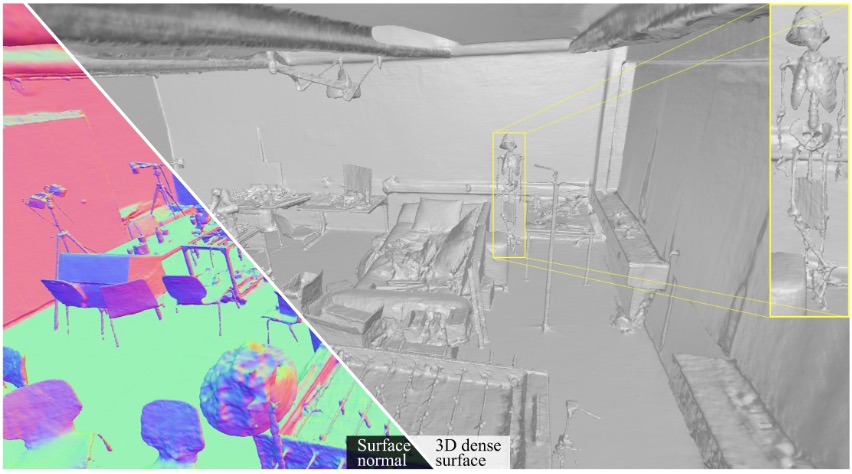
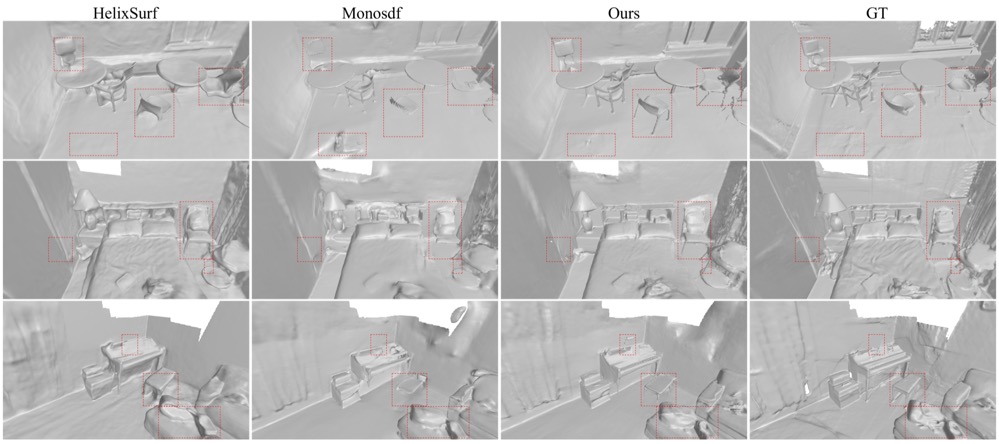
Ziyu Tang, Weicai Ye†, Yifan Wang, Di Huang, Hujun Bao, Tong He†, Guofeng Zhang ICLR 2025, Spotlight, Score: 8886 project page / arXiv / code / More results Proposed Normal Deflection fields to represent the angle deviation between the scene normals and the prior normals, achieving smooth surfaces with fine-grained structures, outperforming MonoSDF. |
|
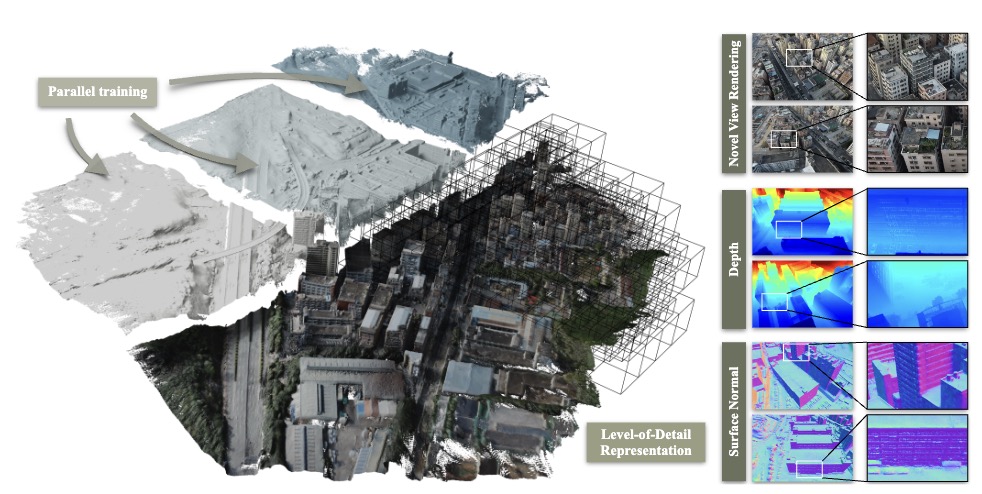
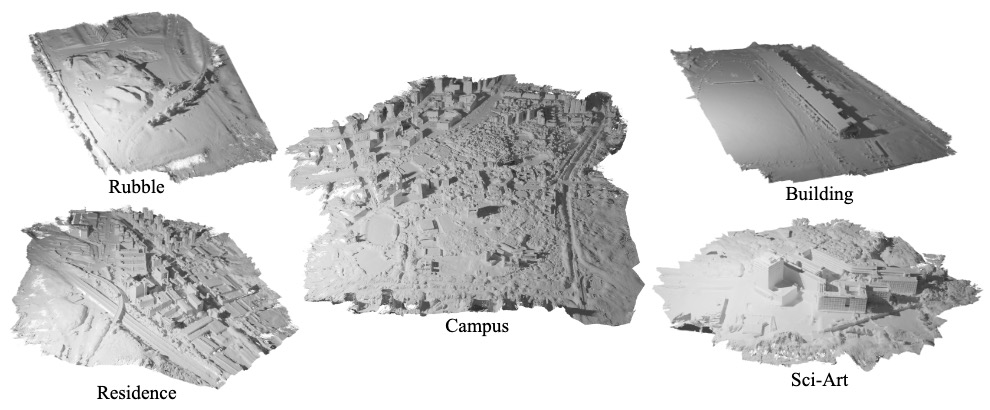
Junyi Chen*, Weicai Ye*†‡, Yifan Wang, Danpeng Chen, Di Huang, Wanli Ouyang, Guofeng Zhang, Yu Qiao, Tong He† AAAI 2025 project page / arXiv / code / More results Based on PGSR, proposed photorealistic rendering and efficient high-fidelity large surface reconstruction in a divide-and-conquer manner with LOD structure, outperforming Neuralangelo. |
|
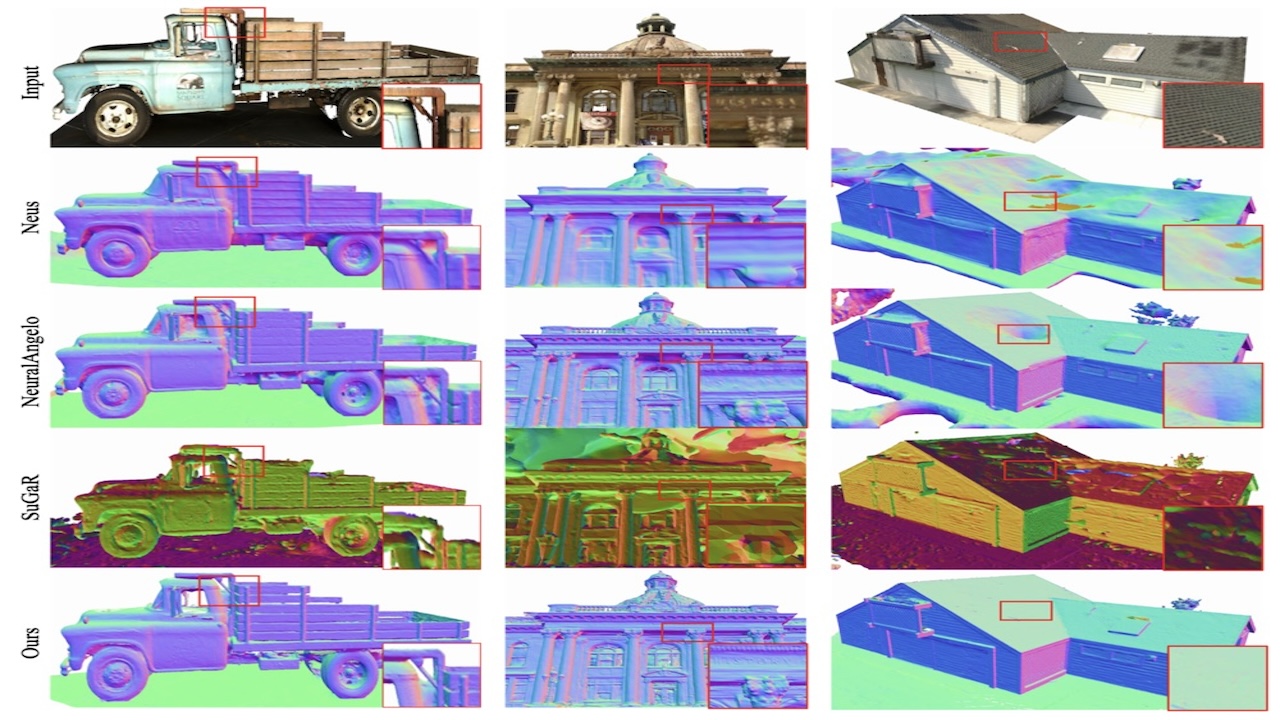
Danpeng Chen, Hai Li, Weicai Ye, Yifan Wang, Weijian Xie, Shangjin Zhai, Nan Wang, Haomin Liu, Hujun Bao, Guofeng Zhang TVCG 2024 project page / arXiv / code / Result1 / Result2 Proposed photorealistic rendering and efficient high-fidelity surface reconstruction model without any pretrained priors, outperforming 3DGS-based (Sugar, 2DGS, Gaussian Opacity Fields, etc.) and SDF-Based methods on T&T, DTU, etc. with faster training. e.g. (ours: only 1 hour vs Neuralangelo 128+ hours) |

|
Weicai Ye*‡ , Chenhao Ji*, Zheng Chen, Junyao Gao, Xiaoshui Huang, Song-Hai Zhang, Wanli Ouyang, Tong He†, Cairong Zhao†, Guofeng Zhang† NeurIPS 2024 project page / arXiv / code Proposed scalable and consistent text-to-panorama generation with spherical epipolar-aware diffusion. Established large-scale panoramic video-text datasets with corresponding depth and camera poses. Achieved long-term, consistent, and diverse panoramic scene generation given unseen text and camera poses with SOTA performance. |

|
Yifan Wang, Di Huang, Weicai Ye†, Guofeng Zhang, Wanli Ouyang, Tong He† NeurIPS 2024 project page / arXiv / code / result1 / result2 Identified two main factors of the SDF-based approach that degrade surface quality and proposed a two-stage neural surface reconstruction framework without any pretrained priors, achieving faster training (only 18 GPU hours) and high-fidelity surface reconstruction with fine-grained details, outperforming Neuralangelo on T&T, ScanNet++, etc. |
|
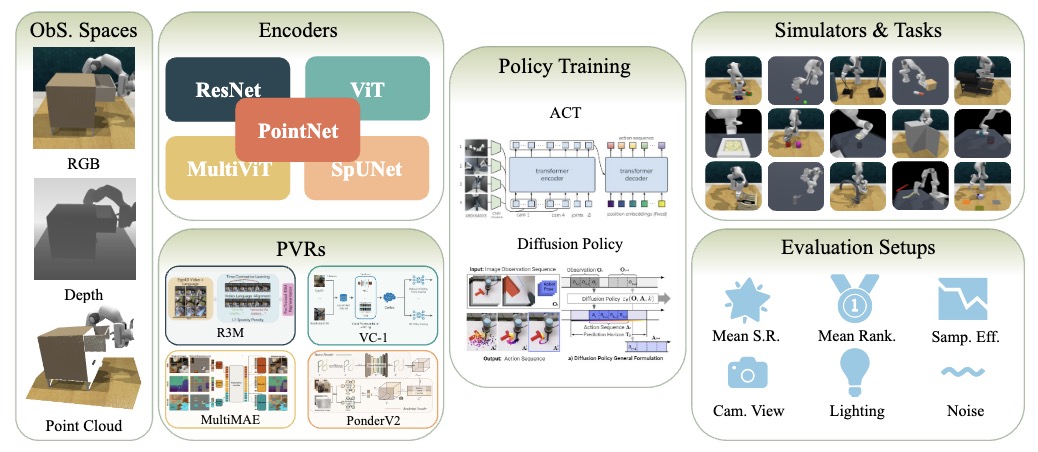
Haoyi Zhu, Yating Wang, Di Huang, Weicai Ye, Wanli Ouyang, Tong He NeurIPS 2024 Datasets and Benchmarks Track project page / arXiv / code Implied that point cloud observation, or explicit 3D information, matters for robot learning. With point cloud as input, the agent achieved higher mean success rates and exhibited better generalization ability. |
|
Hao Li, Yuanyuan Gao, Haosong Peng, Chenming Wu, Weicai Ye, Yufeng Zhan, Chen Zhao, Dingwen Zhang, Jingdong Wang, Junwei Han ICRA 2025 project page / arXiv / code Proposed a novel distributed framework for efficient Gaussian reconstruction for sparse-view vast scenes, leveraging feed-forward Gaussian model for fast inference and a global alignment algorithm to ensure geometric consistency. |

|
Weiwei Cai, Weicai Ye†‡, Peng Ye, Tong He, Tao Chen† Arxiv 2024, Under Review project page / arXiv / code Based on PGSR, proposed the DynaSurfGS framework, which can facilitate real-time photorealistic rendering and dynamic high-fidelity surface reconstruction, achieving smooth surfaces with meticulous geometry. |

|
Xiao Cui* Weicai Ye*†‡, Yifan Wang, Guofeng Zhang, Wengang Zhou, Tong He†, Houqiang Li TCSVT 2025 project page / arXiv / code Based on PGSR, proposed photorealistic rendering and efficient high-fidelity Large Scene Surface Reconstruction for Urban Street Scenes with Free Camera Trajectories, outperforming F2NeRF. |

|
Weicai Ye‡, Xinyu Chen, Ruohao Zhan, Di Huang, Xiaoshui Huang, Haoyi Zhu, Hujun Bao, Wanli Ouyang, Tong He†, Guofeng Zhang† Arxiv 2024 project page / arXiv / code Proposed a concise, elegant, and robust SfM pipeline with point tracking for smooth camera trajectories and dense pointclouds from casual monocular videos. |
|
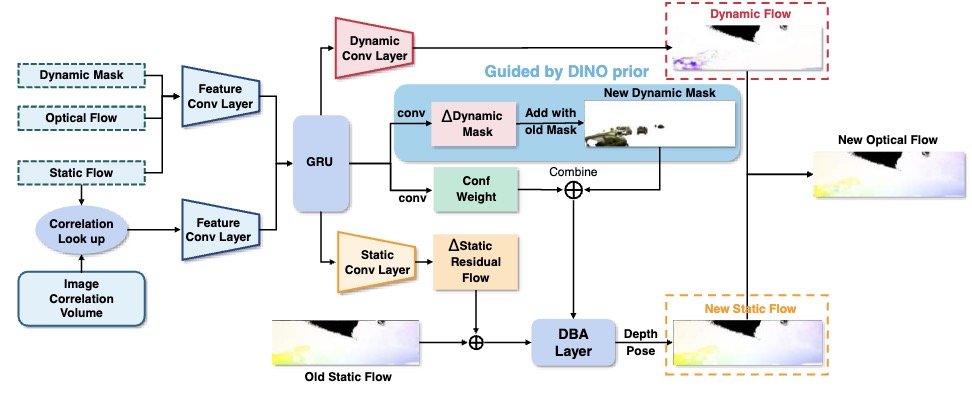
Xingyuan Yu*, Weicai Ye*‡, Xiyue Guo, Yuhang Ming, Jinyu Li, Hujun Bao, Zhaopeng Cui, Guofeng Zhang† Arxiv 2024, Under Review project page / arXiv / code Proposed self-supervised dynamic SLAM with Flow Motion Decomposition and DINO Guidance, outperforming DROID-SLAM. |
|
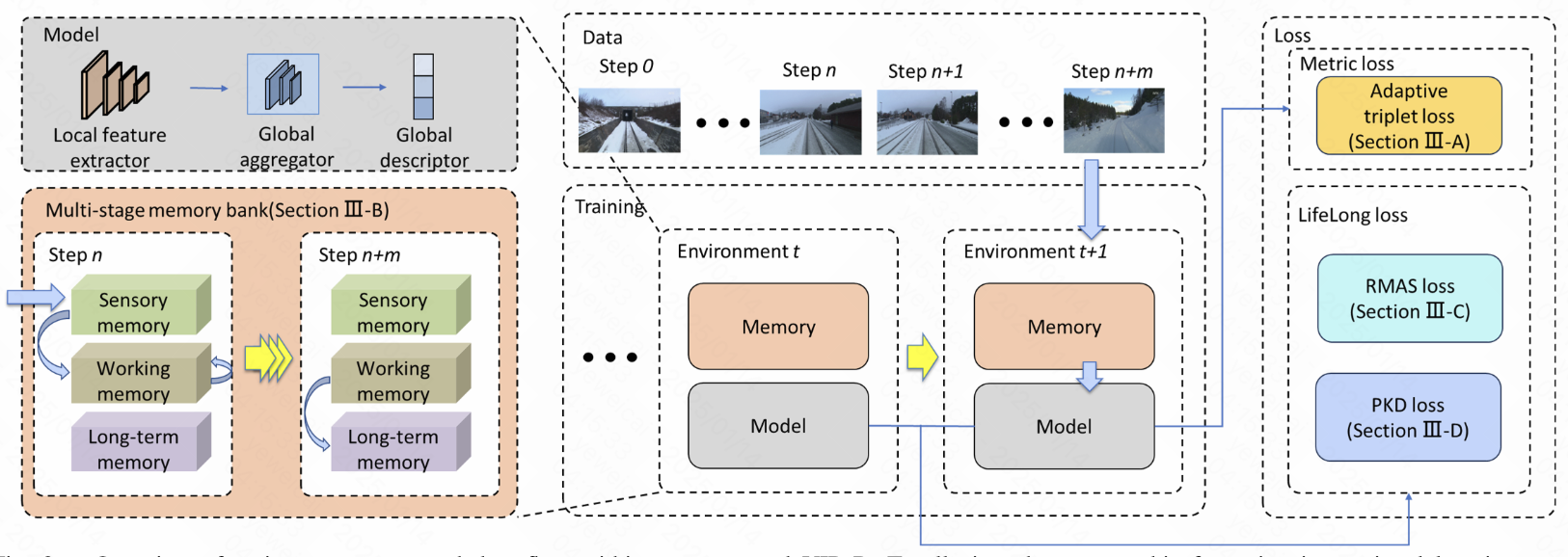
Yuhang Ming, Minyang Xu, Xingrui Yang, Weicai Ye, Weihan Wang, Yong Peng, Weichen Dai, Wanzeng Kong RA-L 2025 project page / arXiv / code Proposed a visual incremental place recognition method with adaptive mining and lifelong learning |
|
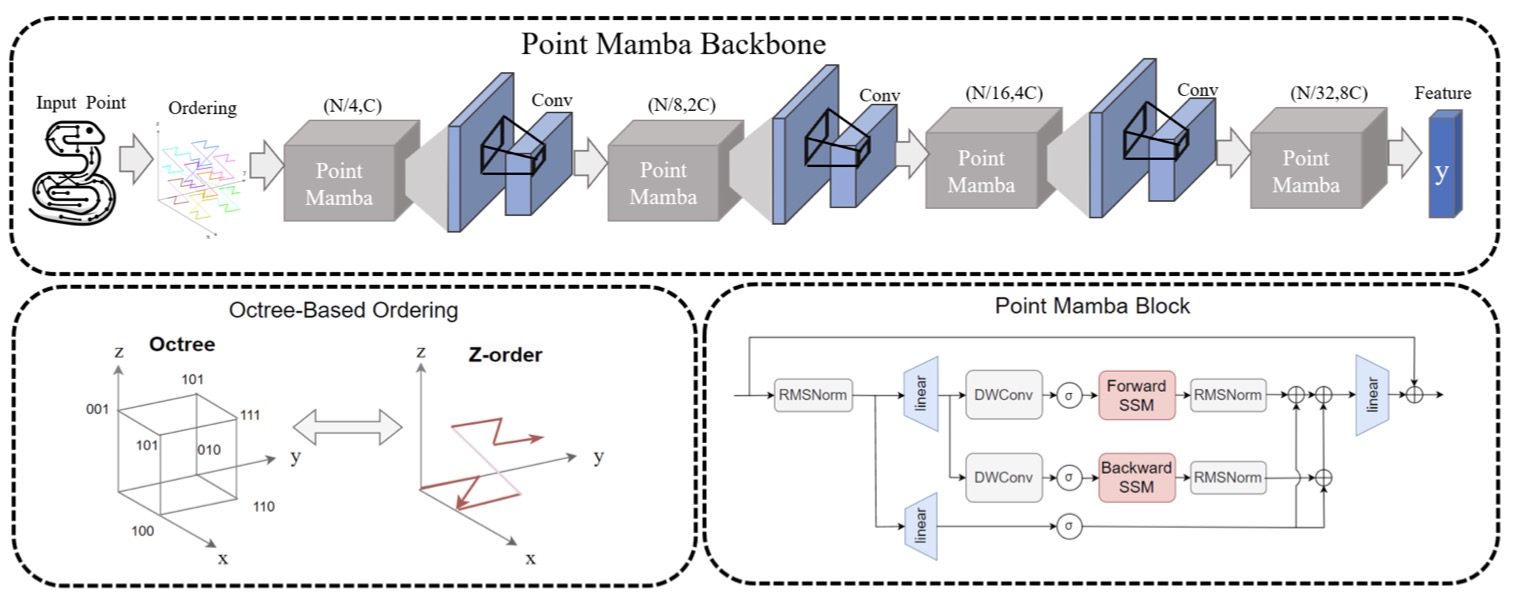
Jiuming Liu, Ruiji Yu, Yian Wang, Yu Zheng, Tianchen Deng, Weicai Ye, Hesheng Wang Arxiv 2024, Under Review project page / arXiv / code Proposed efficient point cloud backbone with Mamba framework and achieved SOTA performance. |
|
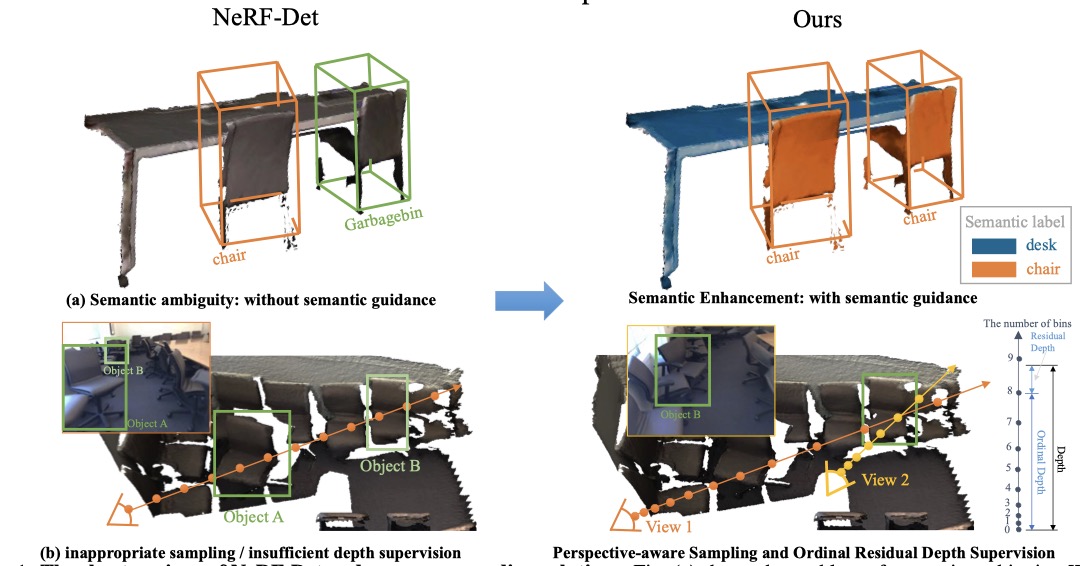
Chenxi Huang, Yuenan Hou, Weicai Ye, Di Huang, Xiaoshui Huang, Binbin Lin, Deng Cai, Wanli Ouyang TIP 2025 project page / arXiv / code / Video Incorporating semantic cues and perspective-aware depth supervision, NeRF-Det++ outperforms NeRF-Det by +1.9% in mAP@0.25 and +3.5% in mAP@0.50 on ScanNetV2. |
|
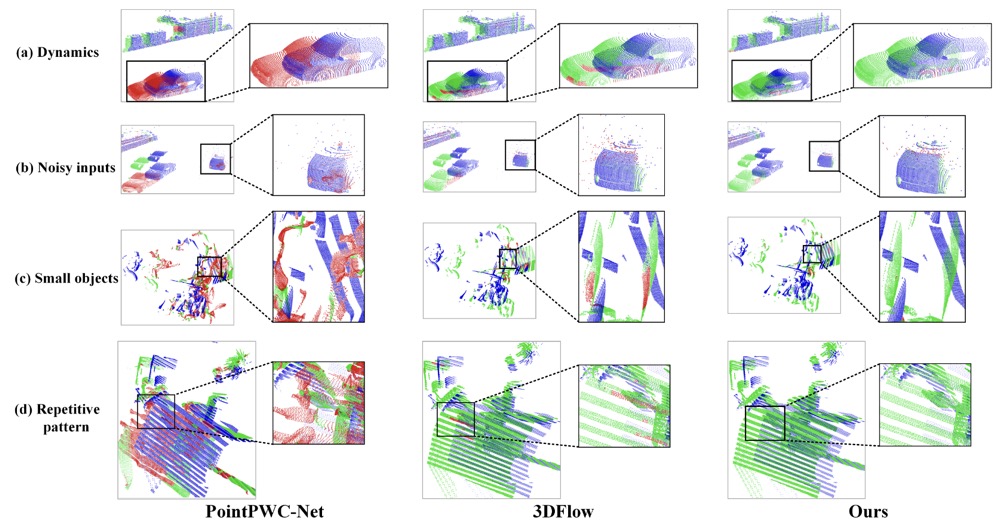
Jiuming Liu, Guangming Wang, Weicai Ye, Chaokang Jiang, Jinru Han, Zhe Liu, Guofeng Zhang, Dalong Du, Hesheng Wang CVPR 2024 arXiv / code / demo Proposed plug-and-play and iterative diffusion refinement framework for robust scene flow estimation. Achieved unprecedented millimeter level accuracy on KITTI, and with 6.7% and 19.1% EPE3D reduction respectively on FlyingThings3D and KITTI 2015. |
|
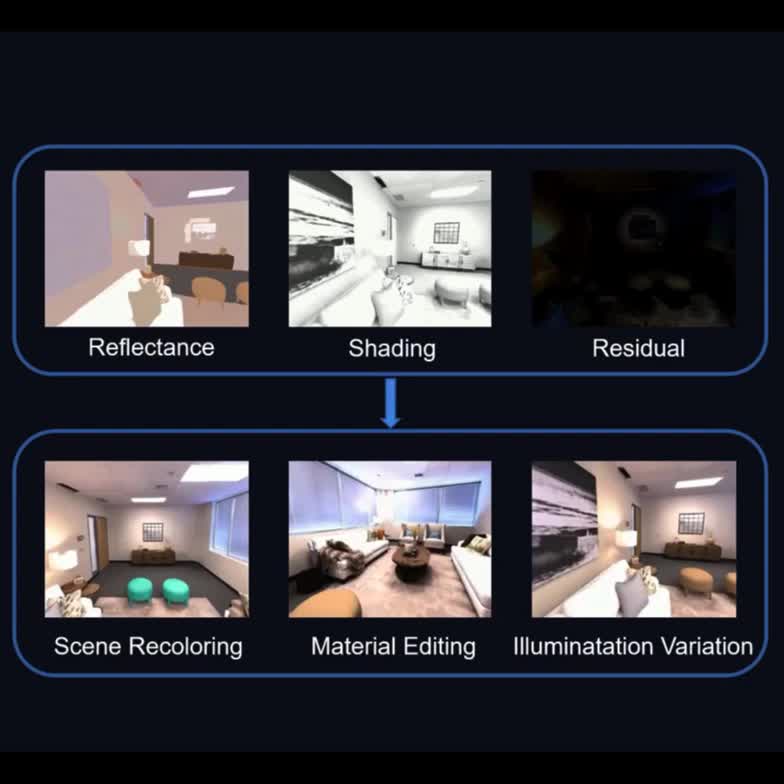
Weicai Ye*, Shuo Chen*, Chong Bao, Hujun Bao, Marc Pollefeys, Zhaopeng Cui, Guofeng Zhang ICCV 2023 project page / arXiv / code / poster Introduced intrinsic decomposition into the NeRF-based rendering and performed editable novel view synthesis in room-scale scenes. |
|
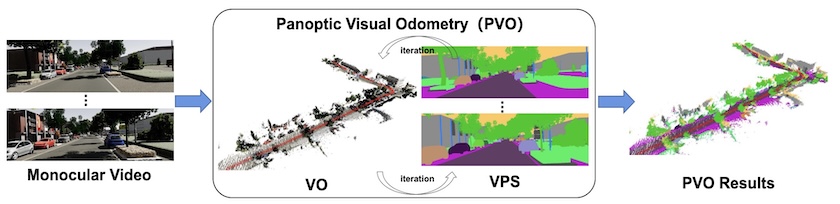
Weicai Ye*, Xinyue Lan*, Shuo Chen, Yuhang Ming, Xingyuan Yu, Zhaopeng Cui, Hujun Bao, Guofeng Zhang CVPR 2023 project page / arXiv / code / poster Introduced panoptic visual odometry framework to achieve comprehensive modeling of the scene motion, geometry, and panoptic segmentation information. |

|
Weicai Ye*, Xingyuan Yu*, Xinyue Lan, Yuhang Ming, Jinyu Li, Zhaopeng Cui, Hujun Bao, Guofeng Zhang Arxiv 2022 Project / code / arxiv Proposed a novel dual-flow representation of selfsupervised scene motion decomposition for dynamic dense SLAM |
|
Yuhang Ming, Weicai Ye, Andrew Calway Arxiv 2022 arXiv / video Proposed a novel end-to-end RGB-D SLAM, which adopts a feature-based deep neural tracker as frontend and a NeRF-based neural implicit mapper as the backend. |

|
Hailin Yu, Youji Feng, Weicai Ye, Mingxuan Jiang, Hujun Bao, Guofeng Zhang Arxiv 2022 arxiv / code / video / As a main solution for feature matching and visual localization, integrated into OpenXRLab. |
|
|
Weicai Ye*, Xinyue Lan*, Ge Su, Zhaopeng Cui, Hujun Bao, Guofeng Zhang Arxiv 2022 arxiv / video Achieved SOTA performance on video panoptic segmentation from two perspectives: feature space (Instance Tracker) and spatial location (Pixel Tracker). |

|
Xiangyu Liu, Weicai Ye, Chaoran Tian, Zhaopeng Cui, Hujun Bao, Guofeng Zhang IROS 2021, Best Paper Award Finalist on Safety, Security, and Rescue Robotics in memory of Motohiro Kisoi. project page / arXiv / code / video Proposed an efficient system named Coxgraph for multi-robot collaborative dense reconstruction in real-time. To facilitate transmission, we propose a compact 3D representation which transforms the SDF submap to mesh packs. |


|
Tianxiang Zhang, Chong Bao, Hongjia Zhai, Jiazhen Xia, Weicai Ye‡, Guofeng Zhang CyberSciTech 2021 paper / video Proposed a multi-device integrated cargo loading management system with AR, which monitors cargoes by fusing perceptual information from multiple devices in real-time. |
|
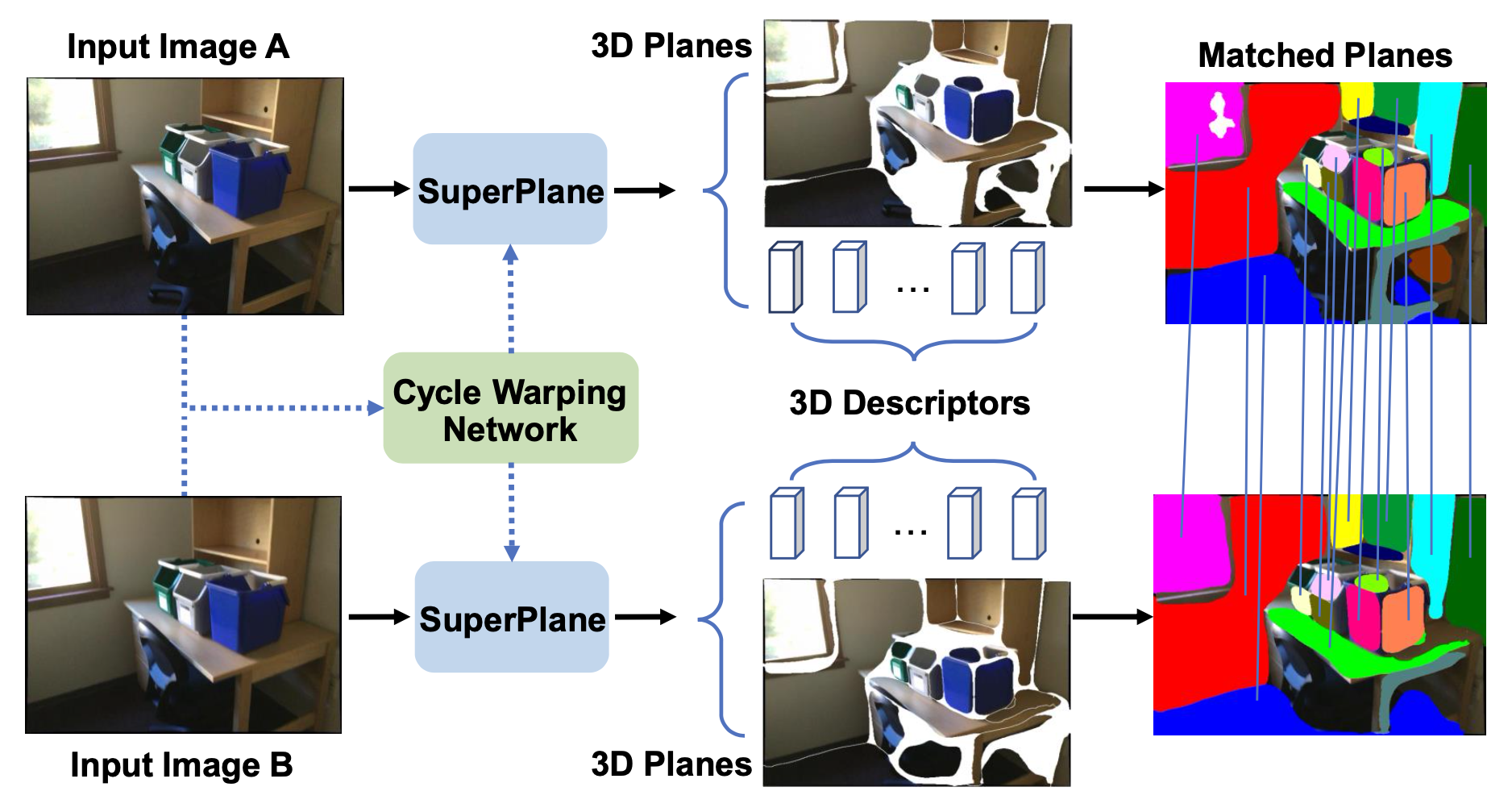
Weicai Ye, Hai Li, Tianxiang Zhang, Xiaowei Zhou, Hujun Bao, Guofeng Zhang VR 2021 paper / video Introduced robust plane matching in texture-less scenes and achieved SOTA performance in image-based localization. |
|
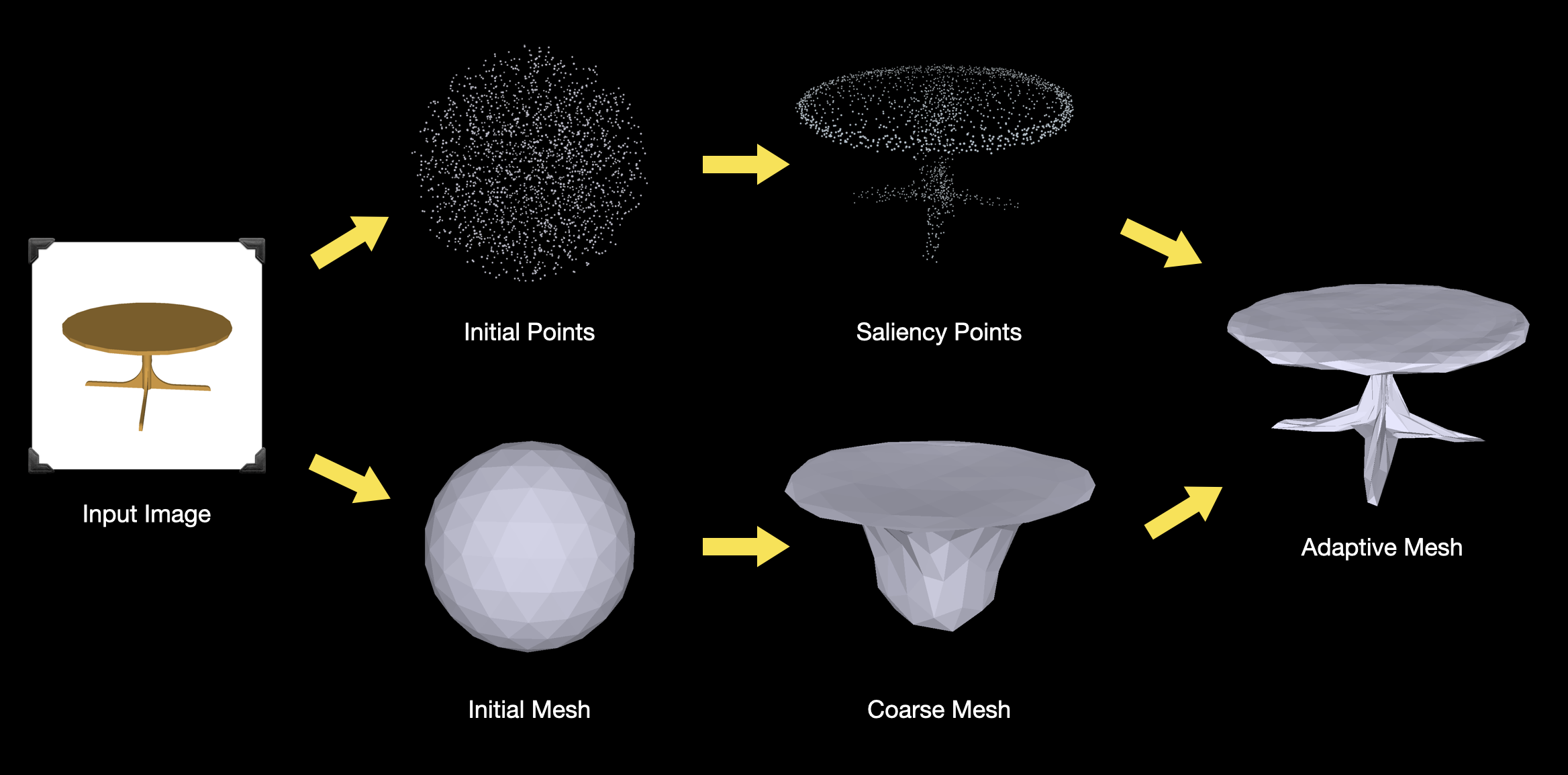
Hai Li*, Weicai Ye*, Guofeng Zhang, Sanyuan Zhang, Hujun Bao 3DV 2020 paper / video / poster / slides Proposed a novel saliency guided subdivision method to achieve the trade-off between detail generation and memory consumption. Our method can both produce visually pleasing mesh reconstruction results with fine details and achieve better performance. |

|
Hailin Yu, Weicai Ye, Youji Feng, Hujun Bao, Guofeng Zhang ISMAR 2020 paper / poster Proposed bipartite graph network with Hungarian pooling layer to deal with 2D-3D matching, which can find more correct matches and improves localization on both the robustness and accuracy. |
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
|
|
 |
Multi-modal Video Generative Foundation models
Slides Valse Webinar, 2025.03.12 |
|
|
 |
Researcher Intern
General 3D Vision Team, Shanghai AI Laboratory As the first author/corresponding author/project lead, proposed InternVerse (Reconstruction Foundation Models include CoSurfGS, GigaGS, StreetSurfGS, NeuRodin), DiffPano (Text to Multi-view Panorama Generation), etc. Working with Dr. Tong He, Prof. Wanli Ouyang, and Prof. Yu Qiao. Mentoring 10+ junior researchers at Shanghai AI Lab. 2023.10-2024.09 |
 |
Visiting Researcher
Computer Vision and Geometry Lab, ETH Zürich, advised by Prof. Marc Pollefeys 2022.09-2023.03 |
 |
3D Vision Researcher Intern
3D Reconstruction of Indoor Scene of RGB-D Images, Sensetime 2018.01-2018.05 |
 |
Software Engineer Intern
Video Search System, Baidu 2017.02-2017.07 |
|
|
|
|
|
|
|
Design and source code from Jon Barron's website |